动态载入有好几个问题:
- 需要时间载入,每次引用都要重定位
- 让
.text区域不能共享,浪费了RAM空间 .text必须能写入带来安全问题
PIC能解决这些问题:
PIC背后的思想很简单,为代码中的全局数据和函数引用外加一层重定向。通过利用链接和加载过程,可能让共享库中的text部分完全位置无关。它可以被映射到不同的内存地址无需修改。
洞见1:text和data段之间的偏移
PIC依赖于数据段和代码段之间的偏移,这些数据在链接时就被链接器知道了。当链接结合几个目标文件时,链接器手机不同目标文件的各个段然后合成一个。因此,链接器知道段的尺寸相对位置。
比如说数据段紧接着代码段,在代码段中引用数据段中某个数据的相对地址就能通过简单的计算得到。当前代码在代码段中的偏移已知,代码段基址与数据段之间的偏移已知,调用的相对地址就是两者之差。
(地址由低到高,位置都是已知的)
text基址
...
某需要相对引用指令-------\
... |
data基址 |相对地址
... |
被引用的数据 -------/
...
洞见2:基于程序指针的取址
x86没有对eip操作的指令,不能通过程序指针取地址,但x64可以啊
x86很多指令需要绝对地址,通过相对与程序指针取址可以得到。
很多shellcode用这个获取程序指针:
call something
something:
pop ebx
ebx中现在就是程序指针的值了
数据索引
全局偏移表(GOT)
面试被问及这个怎么组织的?我不是很明白什么意思。早年曾经就跟着这篇文章打开gdb很好奇的看got/plt是怎么回事。
通过以上两个洞见,在x86上实现PIC也是可能的。通过GOT完成。
GOT就是一个地址表,在数据段中。当一个代码段中的指令想引用某个变量,不是直接通过绝对地址(需要重定位),而是引用GOT中的条目。显然GOT的地址确定,GOT的条目则将保存变量的绝对地址。
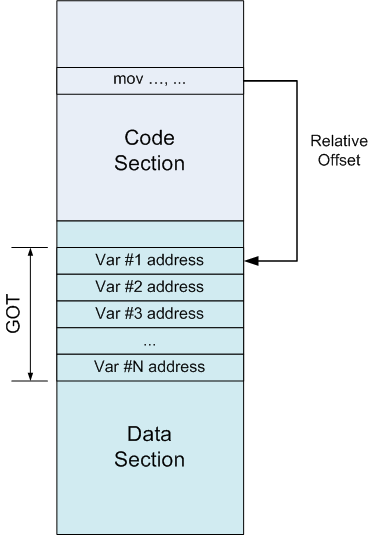
GOT中的条目还是得重定位= =,但相对于载入时重定位,有两个好处
- 重定位每个变量只重定位一次
- 数据段是可写的,不被进程共享。添加重定位没什么影响。将重定位从代码段移过来,让代码段只读并且在进程间可以共享。
一个例子
ml_main_pic.c
1 |
int myglob = 42; |
编译为PIC的动态库
~/Work/project/blackhat/eli gcc -fPIC -m32 -g -shared ml_main_pic.c -o libmlpic.so
反汇编
~/Work/project/blackhat/eli objdump -d -Mintel libmlpic_dataonly.so
libmlpic_dataonly.so: file format elf32-i386
...
0000053c <ml_func>:
53c: 55 push ebp
53d: 89 e5 mov ebp,esp
53f: e8 1a 00 00 00 call 55e <__x86.get_pc_thunk.cx>
544: 81 c1 bc 1a 00 00 add ecx,0x1abc
54a: 8b 81 ec ff ff ff mov eax,DWORD PTR [ecx-0x14]
550: 8b 10 mov edx,DWORD PTR [eax]
552: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
555: 01 c2 add edx,eax
557: 8b 45 0c mov eax,DWORD PTR [ebp+0xc]
55a: 01 d0 add eax,edx
55c: 5d pop ebp
55d: c3 ret
0000055e <__x86.get_pc_thunk.cx>:
55e: 8b 0c 24 mov ecx,DWORD PTR [esp]
561: c3 ret
562: 66 90 xchg ax,ax
53f是获取程序指针的方法,把程序指针放到ecx中。
在544后,ecx就持有GOT的地址。
54a后,将myglob在GOT中的的绝对地址放入eax
550后,myglob的值被置入edx
然后就是简单的加上a和b。
通过readelf可以查看共享库文件中GOT节信息
~/Work/project/blackhat/eli readelf -S libmlpic_dataonly.so
There are 33 section headers, starting at offset 0x1320:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
...
[19] .got PROGBITS 00001fe8 000fe8 000018 04 WA 0 0 4
[20] .got.plt PROGBITS 00002000 001000 000014 04 WA 0 0 4
...
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings)
I (info), L (link order), G (group), T (TLS), E (exclude), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
我们算算ELF中写的和编译器做的是否符合。
0x544+0x1abc=0x2000
正好是.got.plt节的虚拟地址。再计算下myglob地址在GOT中的位置
0x2000-0x14=0x1fec
我们看看ELF文件中的信息:
~/Work/project/blackhat/eli readelf -r libmlpic_dataonly.so
Relocation section '.rel.dyn' at offset 0x358 contains 9 entries:
Offset Info Type Sym.Value Sym. Name
...
00001fec 00000606 R_386_GLOB_DAT 00002018 myglob
...
正好,这里有个重定位。这个重定位就是让链接器把符号地址直接放到这里。
通过gdb看看:
~/Work/project/blackhat/eli gcc -m32 -o driver driver.o -L. -lmlpic_dataonly
~/Work/project/blackhat/eli gdb -q driver
Reading symbols from /home/lyy/Work/project/blackhat/eli/driver...done.
(gdb) break ml_func
Breakpoint 1 at 0x80484c0
(gdb) r
Starting program: /home/lyy/Work/project/blackhat/eli/driver
warning: the debug information found in "/usr/lib64/debug/lib64/ld-2.17.so.debug" does not match "/lib/ld-linux.so.2" (CRC mismatch).
addr myglob = 0x804a024
Breakpoint 1, ml_func (a=1, b=1) at ml_main_pic.c:5
5 return myglob + a + b;
(gdb) disas ml_func
Dump of assembler code for function ml_func:
0xf7fd853c <+0>: push ebp
0xf7fd853d <+1>: mov ebp,esp
0xf7fd853f <+3>: call 0xf7fd855e <__x86.get_pc_thunk.cx>
0xf7fd8544 <+8>: add ecx,0x1abc
=> 0xf7fd854a <+14>: mov eax,DWORD PTR [ecx-0x14]
0xf7fd8550 <+20>: mov edx,DWORD PTR [eax]
0xf7fd8552 <+22>: mov eax,DWORD PTR [ebp+0x8]
0xf7fd8555 <+25>: add edx,eax
0xf7fd8557 <+27>: mov eax,DWORD PTR [ebp+0xc]
0xf7fd855a <+30>: add eax,edx
0xf7fd855c <+32>: pop ebp
0xf7fd855d <+33>: ret
End of assembler dump.
(gdb) i registers
eax 0x1 1
ecx 0xf7fda000 -134373376
...
(gdb) p/x 0xf7fda000-0x14 # GOT中glob绝对地址地址
$2 = 0xf7fd9fec
(gdb) x/x 0xf7fd9fec
0xf7fd9fec: 0x0804a024
(gdb) p &myglob
$4 = (int *) 0x804a024 <myglob>
就是这样
函数调用
额,函数调用,阿里电面时问我GOT干什么的,我说解析函数的吧。。。。。。(就是因为当年看得这篇留下的残缺印象),当时为什么看这篇文章呢?因为发现函数调用竟然都不是直接调用的!!!
函数不是像数据这样简单的引用的。
惰性绑定优化
共享库引用一个函数时,函数地址在载入时才能确定。解析这个地址的过程叫做绑定(binding)。这就是动态载入器把共享库载入进程内存空间时所做的。这个绑定过程不简单,载入器不得不通过在特殊的表中查找函数符号来实现。(共享库ELF目标文件确实有以此为目的的特殊的哈希表节)
解析函数花时间,一般函数比全局变量多太多了,更何况很多函数可能根本不会被调用(比如错误处理或特殊情况)。
为了加速函数绑定的过程,智能惰性绑定机制被设计出来。所谓惰性就是在需要的时候再做什么,计算机科学中很多应用比如惰性求值和copy-on-write
惰性绑定机制通过又一层重定向实现——PLT.
过程链接表(PLT)
PLT是可执行的.text一部分,包含一系列条目(每个条目对应一个共享库调用的外部函数)
每个PLT条目都是段简短的可执行代码。
代码调用PLT中的条目而不是直接调用函数,PLT中条目负责真正调用函数。
这个设计被成为蹦床(‘trampoline’)^1,每个PLT条目对应也在GOT中一个包含函数实际偏移的条目,但仅仅动态载入器解析它后才会对应上。
PLT允许惰性解析,当共享库首次被载入后,函数调用还没被解析:
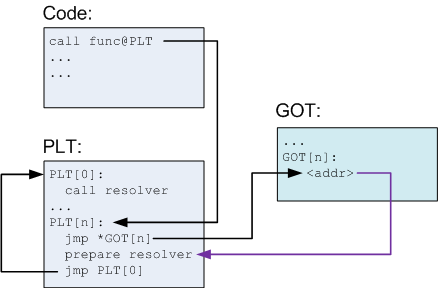
一点解说:PLT的第一个条目调用解析程序,该程序在动态链接器里(每个都有)。这个程序将把函数的实际地址解析。
第一次
于是乎,当func第一次被调用时,调用PLT[n]的例程,接着根据GOT[n]中的内容跳到准备解析的指令,接着调用解析器,解析器会把func函数的实际地址写入GOT[n]然后调用func。
第二次
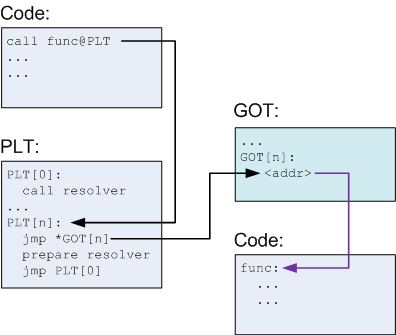
这时候GOT[n]中已经有函数实际地址,从PLT条目直接就跳到函数func的实际代码开始执行。
不再需要解析器,只有一层多余的跳转。这样实际不用的函数永远不用被解析。
同时,这个设计实现了库中代码段完全位置无关。只有GOT中使用了绝对地址,而GOT在数据段中并且会被动态载入器重定位。即使PLT自身都是PIC的,能放到只读的代码段中。
解析器只是一段载入器里的程序,PLT条目中准备的参数,何时的重定向条目帮助它知道需要解析的符号和需要更新的GOT条目。
通过PLT和GOT实现的PIC函数调用——实例
费曼说:What I can not create, I do not understand. 我们自己亲手做做
~/Work/project/blackhat/eli cat ml_main_pic.c
int myglob = 42;
int ml_util_func(int a)
{
return a + 1;
}
int ml_func(int a, int b)
{
int c = b + ml_util_func(a);
myglob += c;
return b + myglob;
}
~/Work/project/blackhat/eli gcc -fPIC -m32 -g -shared ml_main_pic.c -o libmlpic.so
~/Work/project/blackhat/eli objdump -d -Mintel libmlpic.so
libmlpic.so: file format elf32-i386
...
00000440 <ml_util_func@plt>:
440: ff a3 14 00 00 00 jmp DWORD PTR [ebx+0x14]
446: 68 10 00 00 00 push 0x10
44b: e9 c0 ff ff ff jmp 410 <_init+0x30>
...
0000057c <ml_util_func>:
57c: 55 push ebp
57d: 89 e5 mov ebp,esp
57f: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
582: 83 c0 01 add eax,0x1
585: 5d pop ebp
586: c3 ret
00000587 <ml_func>:
587: 55 push ebp
588: 89 e5 mov ebp,esp
58a: 53 push ebx
58b: 83 ec 24 sub esp,0x24
58e: e8 bd fe ff ff call 450 <__x86.get_pc_thunk.bx>
593: 81 c3 6d 1a 00 00 add ebx,0x1a6d
599: 8b 45 08 mov eax,DWORD PTR [ebp+0x8]
59c: 89 04 24 mov DWORD PTR [esp],eax
59f: e8 9c fe ff ff call 440 <ml_util_func@plt>
...
注意59f行的调用,这时ebx是GOT的基址(做减法寻址。。。好奇怪)。
注意440行,PLT条目包含的三部分,一个指向GOT条目中指向的跳转,一个准备解析器参数,一个调用解析器。
我们不在乎410的解析器(PLT[0])
在593的时候获得了eip,接着被加上0x1a6d。GOT的基址就是这个了。
0x593+0x1a6d=0x2000
可以用readelf看看
~/Work/project/blackhat/eli readelf -x .got.plt libmlpic.so
Hex dump of section '.got.plt':
0x00002000 001f0000 00000000 00000000 26040000 ............&...
0x00002010 36040000 46040000 6...F...
条目ml_util_func@plt查看的GOT条目在+0x14位置,即0x2014,上图中可见是0x446
正好是ml_util_func@plt中push那一行。
为了让动态链接器能起作用,重定位条目也被添加来指定在GOT中的哪个位置重定位ml_util_func
~/Work/project/blackhat/eli readelf -r libmlpic.so
Relocation section '.rel.dyn' at offset 0x380 contains 9 entries:
Offset Info Type Sym.Value Sym. Name
00001ef4 00000008 R_386_RELATIVE
00001ef8 00000008 R_386_RELATIVE
00002018 00000008 R_386_RELATIVE
00001fe8 00000106 R_386_GLOB_DAT 00000000 _ITM_deregisterTMClone
00001fec 00000606 R_386_GLOB_DAT 0000201c myglob
00001ff0 00000206 R_386_GLOB_DAT 00000000 __cxa_finalize
00001ff4 00000306 R_386_GLOB_DAT 00000000 __gmon_start__
00001ff8 00000406 R_386_GLOB_DAT 00000000 _Jv_RegisterClasses
00001ffc 00000506 R_386_GLOB_DAT 00000000 _ITM_registerTMCloneTa
Relocation section '.rel.plt' at offset 0x3c8 contains 3 entries:
Offset Info Type Sym.Value Sym. Name
0000200c 00000207 R_386_JUMP_SLOT 00000000 __cxa_finalize
00002010 00000307 R_386_JUMP_SLOT 00000000 __gmon_start__
00002014 00000907 R_386_JUMP_SLOT 0000057c ml_util_func
最后一行很表示载入器应该把符号ml_util_func的地址放入0x2014中(这个函数的GOT条目)
以上是在elf文件中。虽然
我们在gdb中检查首次调用函数后GOT条目的更改:
~/Work/project/blackhat/eli gdb -q ./driver
Reading symbols from /home/lyy/Work/project/blackhat/eli/driver...done.
(gdb) b ml_func
Breakpoint 1 at 0x80484b0
(gdb) run
Starting program: /home/lyy/Work/project/blackhat/eli/./driver
warning: the debug information found in "/usr/lib64/debug/lib64/ld-2.17.so.debug" does not match "/lib/ld-linux.so.2" (CRC mismatch).
addr myglob = 0x804a024
Breakpoint 1, ml_func (a=1, b=1) at ml_main_pic.c:10
10 int c = b + ml_util_func(a);
(gdb) disas ml_func
Dump of assembler code for function ml_func:
0xf7fd8587 <+0>: push ebp
0xf7fd8588 <+1>: mov ebp,esp
0xf7fd858a <+3>: push ebx
0xf7fd858b <+4>: sub esp,0x24
0xf7fd858e <+7>: call 0xf7fd8450 <__x86.get_pc_thunk.bx>
0xf7fd8593 <+12>: add ebx,0x1a6d
=> 0xf7fd8599 <+18>: mov eax,DWORD PTR [ebp+0x8]
0xf7fd859c <+21>: mov DWORD PTR [esp],eax
0xf7fd859f <+24>: call 0xf7fd8440 <ml_util_func@plt>
0xf7fd85a4 <+29>: mov edx,DWORD PTR [ebp+0xc]
0xf7fd85a7 <+32>: add eax,edx
0xf7fd85a9 <+34>: mov DWORD PTR [ebp-0xc],eax
0xf7fd85ac <+37>: mov eax,DWORD PTR [ebx-0x14]
0xf7fd85b2 <+43>: mov edx,DWORD PTR [eax]
0xf7fd85b4 <+45>: mov eax,DWORD PTR [ebp-0xc]
0xf7fd85b7 <+48>: add edx,eax
0xf7fd85b9 <+50>: mov eax,DWORD PTR [ebx-0x14]
0xf7fd85bf <+56>: mov DWORD PTR [eax],edx
0xf7fd85c1 <+58>: mov eax,DWORD PTR [ebx-0x14]
0xf7fd85c7 <+64>: mov edx,DWORD PTR [eax]
0xf7fd85c9 <+66>: mov eax,DWORD PTR [ebp+0xc]
0xf7fd85cc <+69>: add eax,edx
0xf7fd85ce <+71>: add esp,0x24
---Type <return> to continue, or q <return> to quit---q
Quit
(gdb) i registers ebx #GOT基址
ebx 0xf7fda000 -134373376
(gdb) x/x 0xf7fda000+0x14 # GOT中ml_util_func的地址
0xf7fda014: 0xf7fd8446 #和之前ELF文件中类似
(gdb) disas 0xf7fd8440 # ml_util_func@plt
Dump of assembler code for function ml_util_func@plt:
0xf7fd8440 <+0>: jmp DWORD PTR [ebx+0x14]
0xf7fd8446 <+6>: push 0x10
0xf7fd844b <+11>: jmp 0xf7fd8410
End of assembler dump.
调用一次:
(gdb) n
11 myglob += c;
(gdb) x/x 0xf7fda000+0x14
0xf7fda014: 0xf7fd857c
(gdb) p &ml_util_func
$1 = (int (*)(int)) 0xf7fd857c <ml_util_func>
可见GOT条目已经被更改。
通过环境变量控制载入解析
通过LD_BIND_NOW和LD_BIND_NOT来定义加载方式。
man ld.so
PIC的代价
- 所有PIC中外部数据代码引用都需要额外的重定向,需要更多的内存。
- 在x86平台上多占用了一个通用寄存器,结果就需要更多内存引用。
结论
x64的好像作者没有写了。。。。。。。
x64平台上,因为能相对rip寻址,不需要通过某种方式获取程序指针。
关于.got和.got.plt提下,就是为了区分数据和函数引用,一个从GOT基址负引用ebx-0x14一个正引用ebx+0x14。这个设计= =